

Let's take a look at Microsoft's Azure platform where they offer machine learning. I am not real impressed. Well, I should state that it's not really a Microsoft product as they are just using an R package. There is no learning here with the models being actually built. It is fitting and not intelligent modeling. Not machine learning.
The assumptions when you do any kind of modeling/forecasting is that the residuals are random with a constant mean and variance. Many aren't aware of this unless you have taken a course in time series.
Azure is using the R package auto.arima to do it's forecasting. Auto.arima doesn't look for outliers or level shifts or changes in trend, seasonality, parameters or variance.
Here is the monthly data used. 3.479,3.68,3.832,3.941,3.797,3.586,3.508,3.731,3.915,3.844,3.634,3.549,3.557,3.785,3.782,3.601,3.544,3.556,3.65,3.709,3.682,3.511, 3.429,3.51,3.523,3.525,3.626,3.695,3.711,3.711,3.693,3.571,3.509
It is important to note that when presenting examples many will choose a "good example" so that the results can show off a good product. This data set is "safe" as it is on the easier side to model/forecast, but we need to delve into the details that distinguish the difference between real "machine learning" vs. fitting approaches. It's important to note that the data looks like it has been scaled down from a large multiple. Alternatively, if the data isn't scaled and really is 3 digits out then you also are looking for extreme accuracy in your forecast. The point I am going to make now is that there is a small difference in the actual forecasts, but the level(lower) that Autobox delivers makes more sense and that it delivers residuals that are more random. The important term here is "is it robust?" and that is what Box-Jenkins stressed and coined the term "robustness".
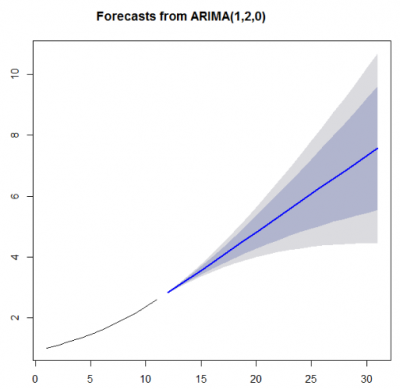
Here is the model when running this using auto.arima. It's not too different than Autobox's except one major item which we will discuss.
. 
The residuals from the model are not random. This is a "red flag". They clearly show the first half of the data above 0 and the second half below zero signaling a "level shift" that is missing in the model.

Now, you could argue that there is an outlier R package with some buzz about it called "tsoutliers" that might help. If you run this using tsoutliers, a SPURIOUS Temporary Change(TC) up (for a bit and then back to the same level is identified at period #4 and another bad outlier at period #13 (AO). It doesn't identify the level shift down and made 2 bad calls so that is "0 for 3". Periods 22 to 33 are at a new level, which is lower. Small but significant. I wonder if MSFT chose not to test use the tsoutliers package here.

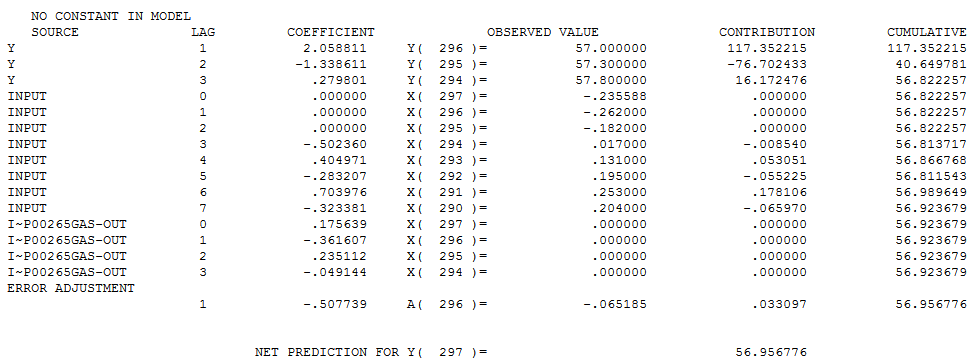
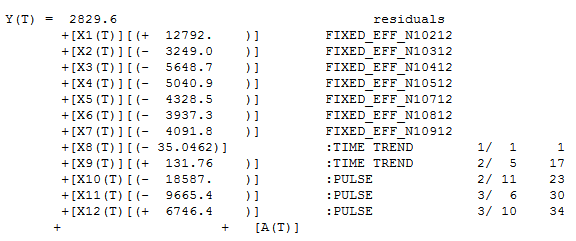
Autobox's model is just about the same, but there is a level shift down beginning at period 11 of a magnitude of .107.
Y(T) = 3.7258 azure
+[X1(T)][(- .107)] :LEVEL SHIFT 1/ 11 11
+ [(1- .864B** 1+ .728B** 2)]**-1 [A(T)]
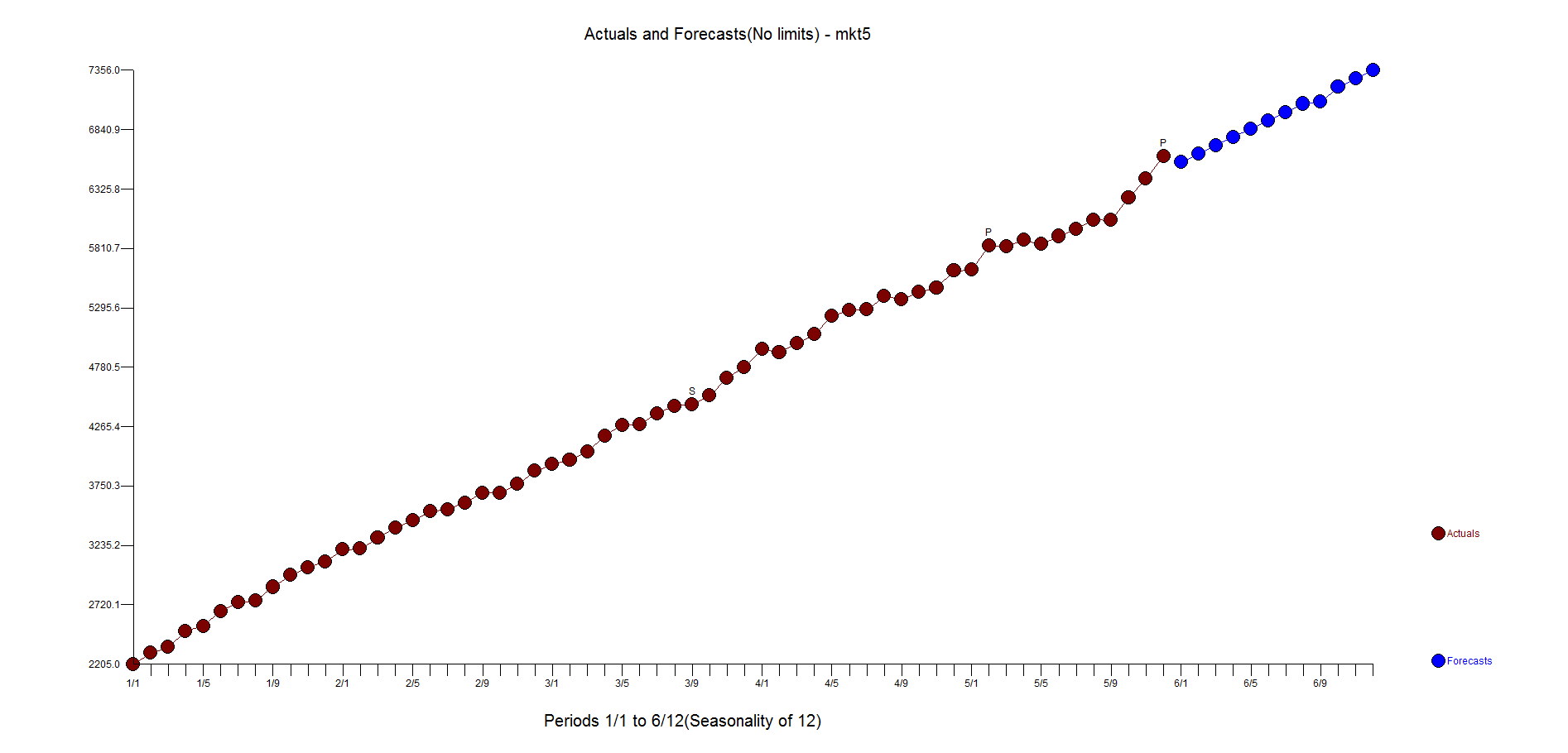
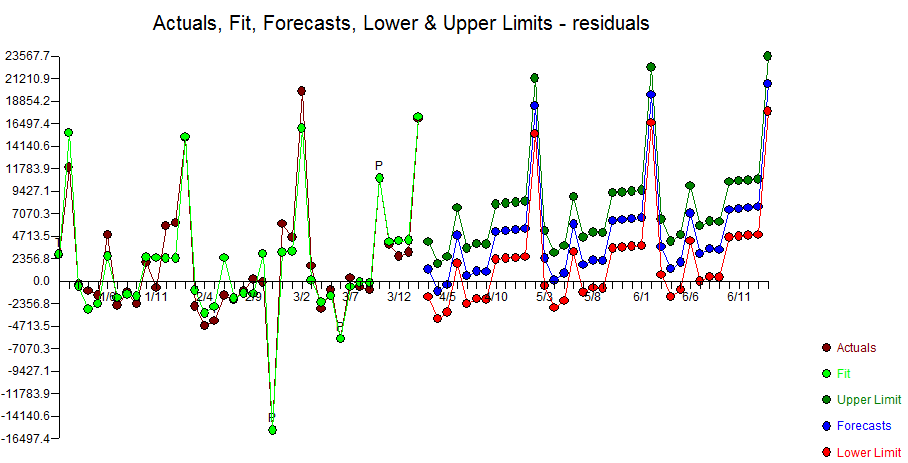
Here are both forecasts. That gap between green and red is what you pay for.

Note that the Autobox upper confidence limits are much lower in level.

Autobox's residuals are random


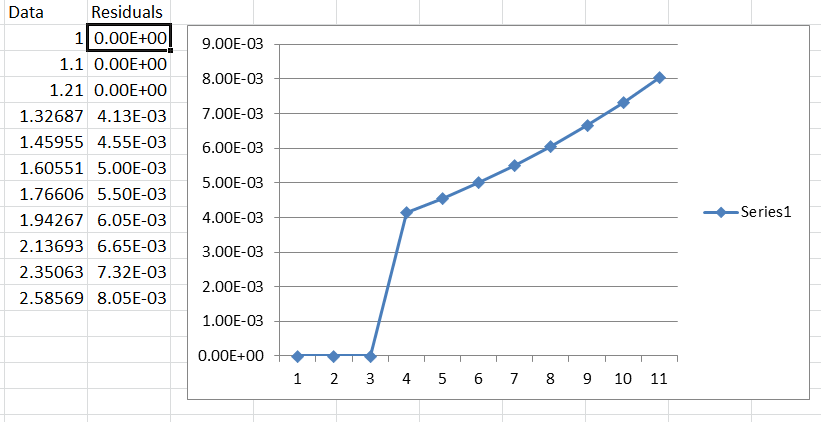 If we ignore the unneeded unit circle constraint, the model would be again double differencing with an AR1 coefficient that is 1.1 and very much OUTSIDE the unit circle and very estimable!
If we ignore the unneeded unit circle constraint, the model would be again double differencing with an AR1 coefficient that is 1.1 and very much OUTSIDE the unit circle and very estimable!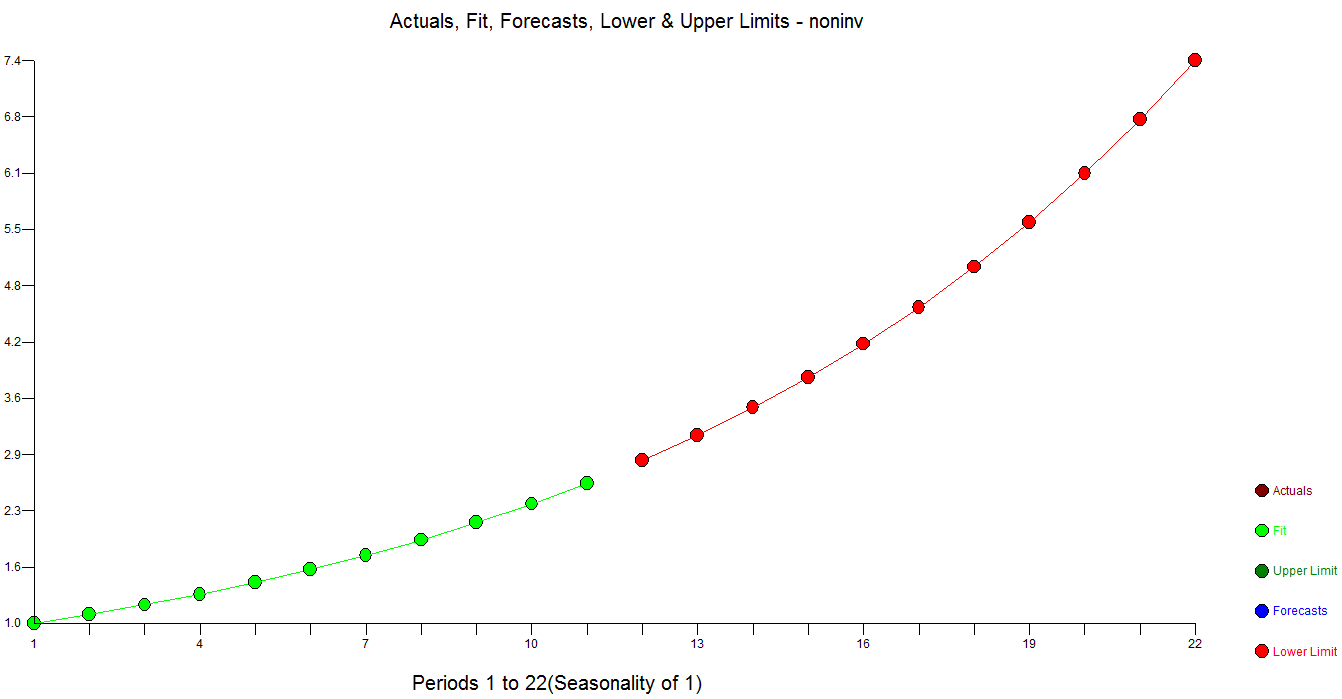




{kind=link}
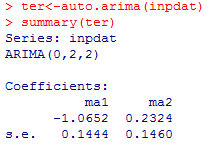{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}