In 2011, IBM Watson shook our world when it beat Ken Jennings on Jeopardy and "Computer beats Man" was the reality we needed to accept.
IBM's WatsonAnalytics is now avalilabe for a 30 day trial and it did not shake my world when it came to time series analysis. They have a free trial to download and play with the tool. You just need to create a spreadsheet with a header record with a name and the data below in a column and then upload the data very easily into the web based tool.
It took two example time series for me to wring my hands and say in my head, "Man beats Computer". Sherlock Holmes said, "It's Elementary my dear Watson". I can say, "It is not Elementary Watson and requires more than pure number crunching using NN or whatever they have".
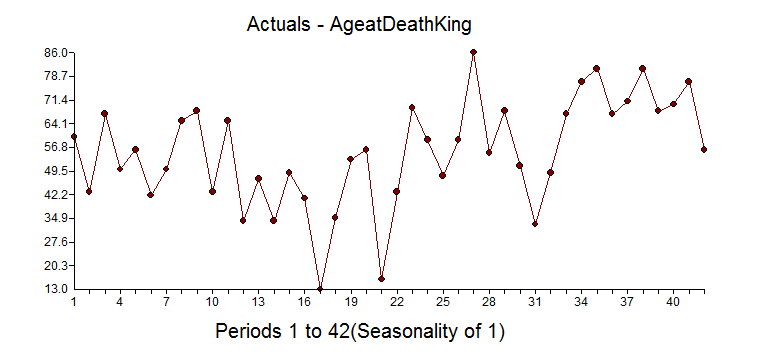
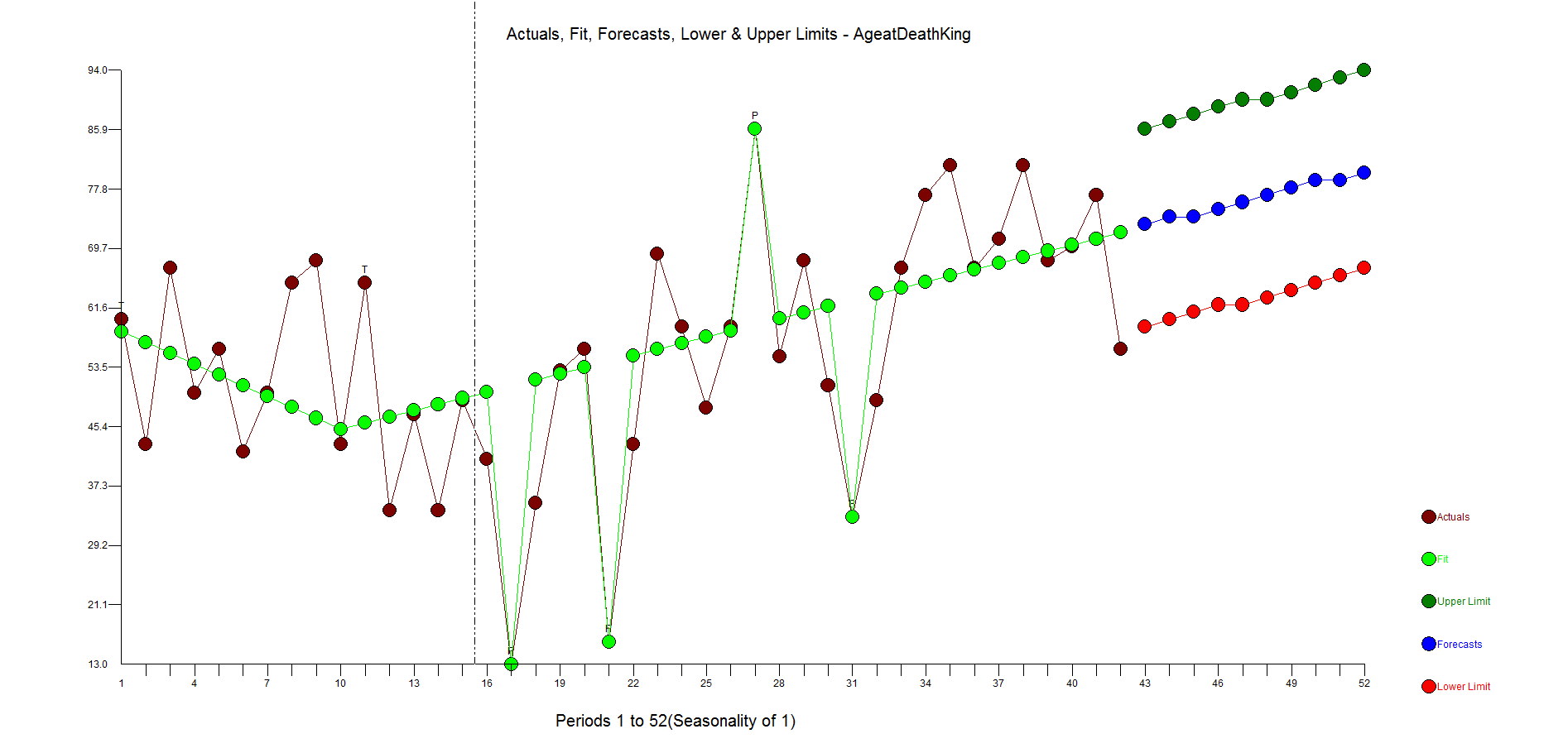
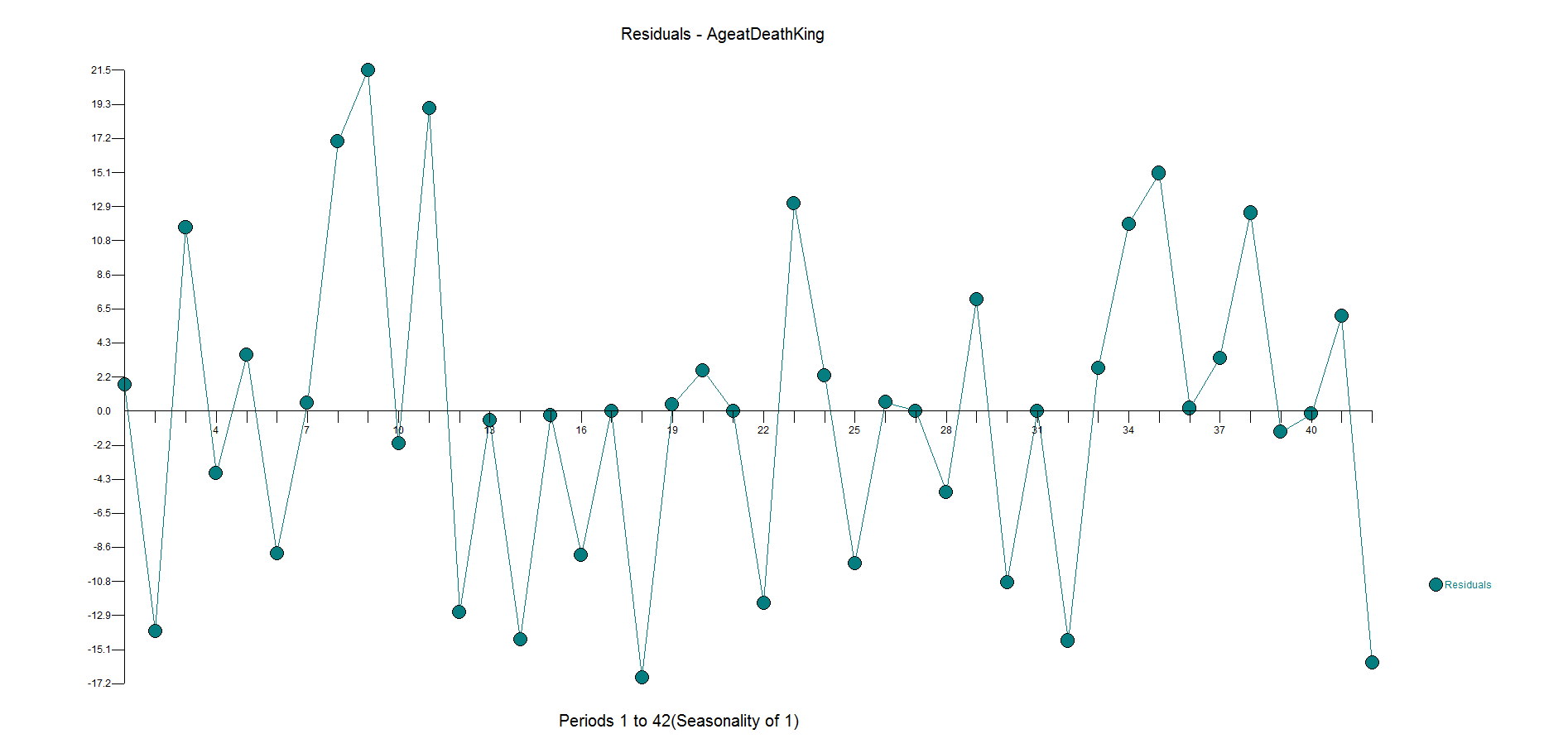
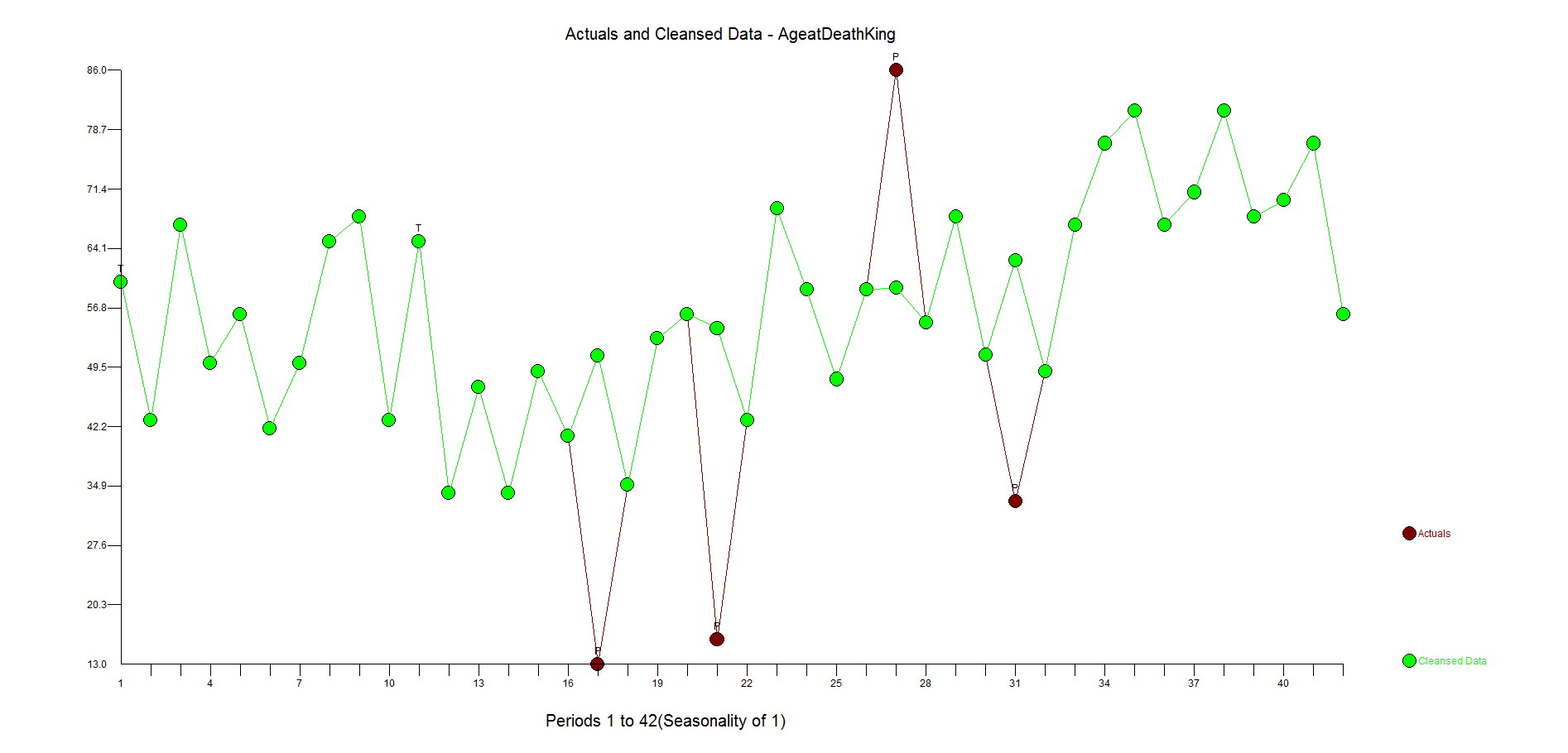
The first example is our classic time series 1,9,1,9,1,9,1,5 to see if Watson could identify the change in the pattern and mark it as an outlier(ie inlier) and continue to forecast 1,9,1,9, etc. It did not. In fact, it expected a causal variable to be present so I take it that Watson is not able to handle Univariate problems, but if anyone else knows differently please let me know.
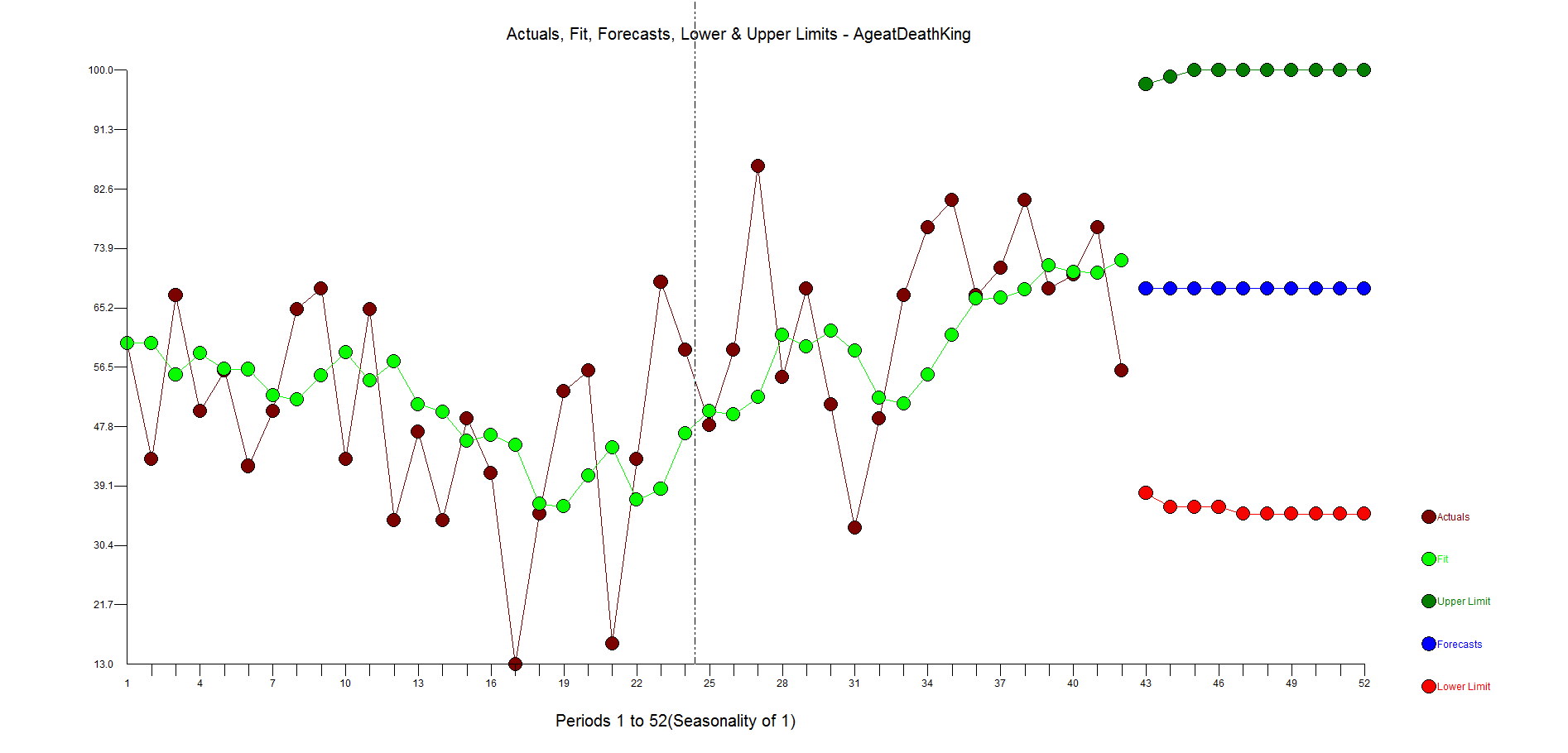
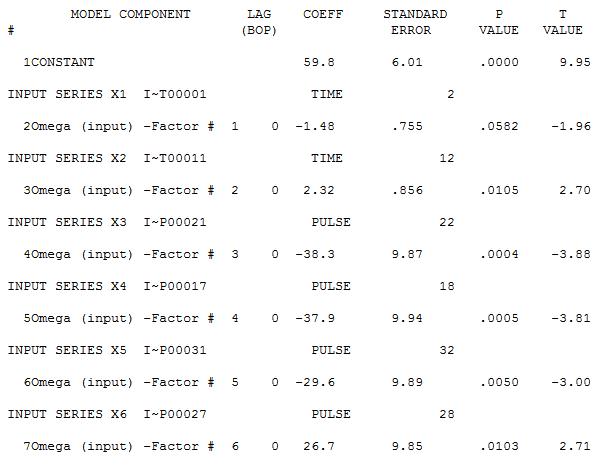
The second example was originally presented in the 1970 Box-Jenkin's text book and is a causal problem referred to as "Gas Furnace" and is described in detail in the textbook and also on NIST.GOV's website. Methane is the X variable and Y is the Carbon Dioxide output. If you know or now closely examine the model on the NIST website, you will see a complicated relationship where there is a complicated relationship between X and Y that occurs with a delay between the impact of X and the effect on Y (see Yt-1 and Yt-2 and Xt-1 and Xt-2 in the equation). Note that the R Squared is above 99.4%! Autobox is able to model this complex relationship uniquely and automatically. Try it out for yourself here! The GASX problem can be found in the "BOXJ" folder which comes with every installed version of Autobox for Windows.
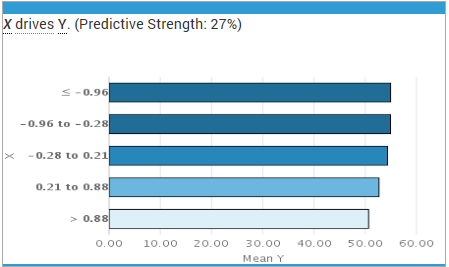
Watson did not find this relationship and offered a predictive strength of only 27%(see the X on the left hand of the graph) compared to 96.4%. Not very good. This is why we benchmark. Please try this yourself and let me know if you see something different here.
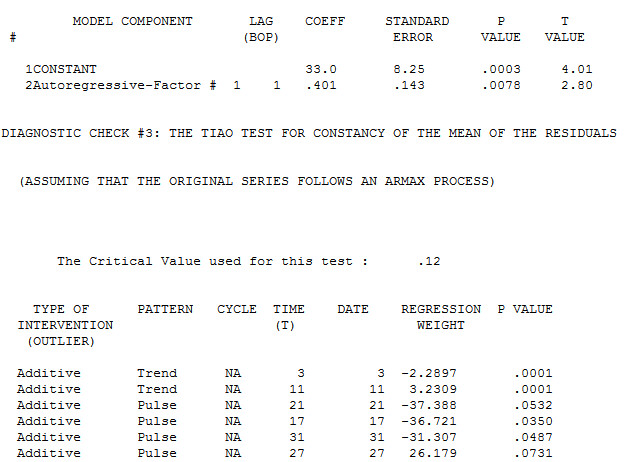
Autobox's model has lags in Y and lags in the X from 0 to 7 periods and finds an outlier(which can occur even in simulated data out of randomness). We show you the model output here in a "regression" model format so it can be understood more easily. We will present the Box-Jenkins version down below.
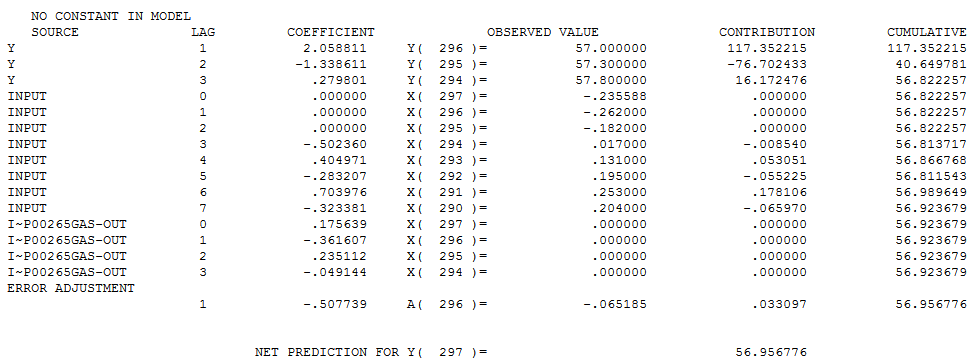
Here is a more parsimonious version of the Autobox model in pure Box-Jenkins notation. Another twist is that Autobox found that the variance increased at period 185 and used Weighted Least Squares to do the analysis hence you will see the words "General Linear Model" at the top of the report.