I am familiar with Regression but I really don't know how it relates to a Transfer Function?
Regression models versus transfer function models
A very natural question arises in the selection and utilization of models.
One asks, "Why not use simple models that provide uncomplicated
solutions?" The answer is very straightforward, "Use enough complexity
to deal with the problem and not an ounce more". Restated, let the
data speak and validate all assumptions underlying the model. Don't
assume a simple model will adequately describe the data. Use
identification/validation schemes to identify the model.
Since regression is a particular subset of a transfer function, it
is possible to constrain the transfer function to deliver regression
results. The following is a development of a transfer function model
from the bottom up. In other words, we will start with a simple model
and allow complications to enter one-by-one. In this manner, we will
show what the real requirements are for a simple regression model.
simple model:
![]()
where Yt = Endogenous (output); B0 = constant; B1 = coefficient for Xt;
Xt = Exogenous (regressor); At = error term
Restating in terms of a more general class, we get:
![]()
Where B0 = k; B1 = W0
Introducing the notion of a polynomial, we get:
![]()
W(B) = W0; and in general Bk Xt = Xt-k
or specifically (1 period lag) B1 Xt = Xt-1 or (no lag) B0 Xt = Xt
Also note that Bk Xt = Xt-k
Incorporating the multiplicative identity element (1) doesn't change anything.
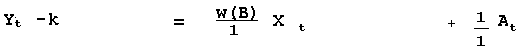
Recognizing that there might be the need for an autoregressive
process to compensate for omitted X's we get the following:
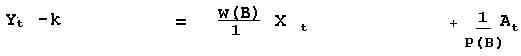
P(B) = 1 for the null case
Recognizing that there might be the need for a moving average
process to compensate for omitted X's we get the following:
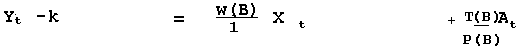
P (B) = 1 ; T(B) = 1 for the null case
In general P(B) = 1 - P1B1 - P2B2 - P3B3 - P4B4 + ……. - PpBp
T(B) = 1 - T1B1 - T2B2 - T3B3 - T4B4 + ……. - TqBq
Recognizing that there might be the need to incorporate a period
of delay (b) before Y responds X we get:
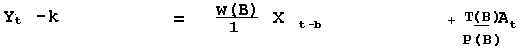
If there is no delay then b=0; b= delay or "dead time" before Y responds to X.
Incorporating the identity element (1) doesn't change anything.
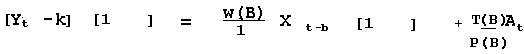
Recognizing the possibility that the level of Y might depend on
changes in X, rather than the level of X suggests:
P(B) = 1 ; T(B) = 1 {[1-Bo]}d = 1 for o =0 & d =0
More generally to reflect the particular series (X).
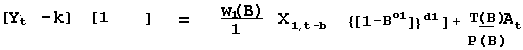
w(B) = w0 where B1 Xt = Xt-1 and in general Bk Xt = Xt-k
b= delay or "dead time"
P(B) = 1 ; T(B) = 1 {[1-Bo1]}d1 = 1 for o1 =0 & d1 =0
Recognizing the possibility that changes in Y might depend on
changes in X, leads to:
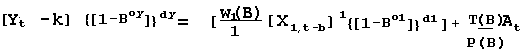
{[1-Boy]}dy = 1 for oy =0 & dy =0
Recognizing the possibility that changes in X effect a sequence of Y's leads to a dynamic
model of:
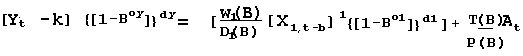
w(B) = w0 where B1 Xt = Xt-1 and in general Bk Xt = Xt-k
b= delay or "dead time"
P(B) = 1 ; T(B)=1; D(B)=1 {[1-Bo1]}d1 = 1 for o1 =0 & d1 =0
{[1-Boy]}dy = 1 for oy =0 & dy =0; W(B)/D(B)=W'(B)
Note that W(B)/D(B) can be non-parsimoniously restated W'(B). We prefer W(B) and D(B) in order to minimize the number of coefficients.
Incorporating the identity element (1) for an appropriate power
transformation to de-couple linear dependence between the first and
second moment delivers:
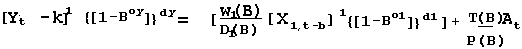
w(B) = w0 where B1 Xt = Xt-1 and in general Bk Xt = Xt-k
b= delay or "dead time"
P(B) = 1 ; T(B)=1; D(B)=1 {[1-Bo1]}d1 = 1 for o1 =0 & d1 =0
{[1-Boy]}dy = 1 for oy =0 & dy =0
Allowing these power transforms (ay , a1) to be other than unity leads to:
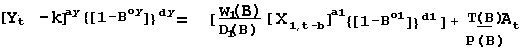
w(B) = w0 where B1 Xt = Xt-1 and in general Bk Xt = Xt-k
b= delay or "dead time"
P(B) = 1 ; T(B)=1; D(B)=1 {[1-Box]}dx = 1 for o1 =0 & d1 =0
a1
= 1; ay = 1; {[1-Boy]}dy = 1 for oy =0 & dy =0
Note that ay and a1
a is the power transformation ranging from:
-1 inverse
.5 inverse square root
0 logarithm
.5 square root
1 none
For n regressor series we get:
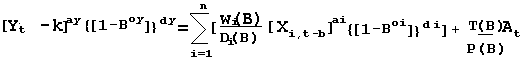
w(B) = w0 where B1 Xt = Xt-1 and in general Bk Xt = Xt-k
b= delay or "dead time"
Thus the ordinary regression model is seen to be a particular
subset of a more powerful class of model where the following set of
assumptions are in place:
. power transforms are known or assumed for all series
. the delay is known b = 0
. the required level of differences is known for all series
. the form of the distributed lag structure W(B) is known for all series
. the form of the dynamic lag structure D(B) is known for all series
. the AR lag structure P(B) is known
. the MA lag structure T(B) is known
These are the restrictions that shackle the transfer function when
you assume the ordinary regression model. Thus the model is:
![]()
SIDEBAR ON KOYCK:
Another ad-hoc model is popularly known as "polynomial distributed
lags".
w(B) = a polynomial of order L, whose coefficients can be described
by a polynomial of the order L.
E.G. A QUADRATIC
LET Wi = ao + ai i + a2 i2
In the Koyck method, these coefficients are assumed to exponentially decay.
NUMERICAL EXAMPLE
Sometimes an example can clear up algebraic confusion.
![]()
generalizing
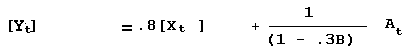
generalizing to include seasonal differencing of order 12 for Y
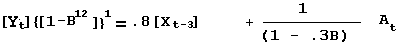
generalizing with a dynamic component; D(B) = 1 - .5B
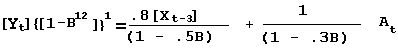
We will revert to no log transformation for simplicity sake. Multiplying through by 1-.3B to clear fractions:
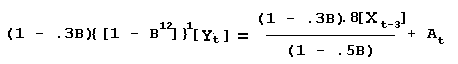
and in a rearranged or expanded form:
Since (1- .3B)(1 - B12 ) = 1 - .3B - B12 + .3B13
We get:
(1-.3B-B12+.3B13) Yt = (.8)[ (1 - .3B)/(1 - .5B)] Xt-3 + At
(1-.3B-B12+.3B13) Yt = (.8)[ (1 - .3B][1 + .5B + .25B2 + .125B3)] Xt-3 + At
(1-.3B-B12+.3B13) Yt = (.8)[ (1 + 2B1 + 1B2 + .5B3 + .25B4 + .125B5 + .0625B6 +…… ] Xt-3 + At
(1-.3B-B12+.3B13) Yt = [.8B0 + 1.6 B1 + .8B2 + .4B3 + .2B4 + .1B5 + .05B6 +…… ] Xt-3 + At
Truncating at lag 9 we get:
(1-.3B-B12+.3B13) Yt = + .8Xt-3 + 1.6Xt-4 + .8Xt-5 + .4Xt-6 + .2Xt-7 + .1BXt-8 + .05Xt-9 + At
leading to:
Yt = .3Yt-1 +Yt-12 - .3Yt-13 + .8 Xt-3 + 1.6 Xt-4 + .8 Xt-5 +.4 Xt-6 + .2 Xt-7 + .1BXt-8 + .05Xt-9 + At
This model that we have built might look like a typical regression model. It does, but the fact remains that we took a much different course…we proceeded through the identification of the model form and arrived with this model. A typical approach might be to start with this model and run it in EVIEWS and whatever variables that aren't significant are removed and presto we have our answer. It should also be noted that the number of coefficients are more than what was really necessary when viewed as a tran sfer function model. This is called overparameterization. When this model is estimated using typical regression the coefficients will be different than the DERIVED coefficients as shown above.
The above equation can be generalized to have >1 endogenous (dependent) variables. This particular problem is referred to as VECTOR ARIMA (VARIMA) where M endogenous variables must be predicted using J exogenous variables. The difference between VECTOR ARIMA and VECTOR Autoregressive (VAR) models as normally implemented is that all variables in VAR are assumed to be endogenous which can be a subpar result.